Ensemble of Pipelines
One of the most common execution patterns consists of mulitple concurrent Pipelines with multiple Stages where each Stage consists of several Tasks. We call this an Ensemble of Pipelines. A pictorial representation of this pattern is provided below.
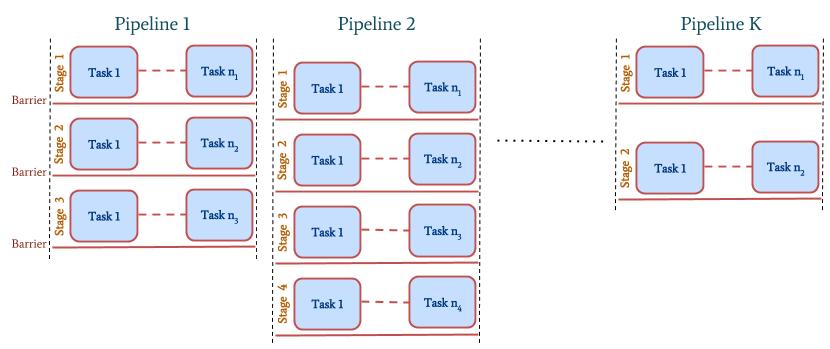
Figure 1: Ensemble of Pipelines
We encourage you to take a look at the Pipeline of Ensembles example on the next page and compare it with the above pattern.
Note
The reader is assumed to be familiar with the PST Model and to have read through the Introduction of Ensemble Toolkit.
Note
This chapter assumes that you have successfully installed Ensemble Toolkit, if not see Installation.
In the following example, we create 10 Pipelines, each with three Stages. The Task in the first Stage creates a file. The Task in the second Stage performs a character count on that file. The Task in the third Stage performs a checksum on the output of the Task from the second stage.
You can download the complete code discussed in this section here or find it in
your virtualenv under share/radical.entk/simple/scripts.
python eop.py
Let’s take a look at the complete code in the example. You can generate a more verbose output by setting the environment
variable RADICAL_ENTK_VERBOSE=DEBUG.
A look at the complete code in this section:
#!/usr/bin/env python
from radical.entk import Pipeline, Stage, Task, AppManager
import os
# ------------------------------------------------------------------------------
# Set default verbosity
if os.environ.get('RADICAL_ENTK_VERBOSE') is None:
os.environ['RADICAL_ENTK_REPORT'] = 'True'
def generate_pipeline():
# Create a Pipeline object
p = Pipeline()
# Create a Stage object
s1 = Stage()
# Create a Task object which creates a file named 'output.txt' of size 1 MB
t1 = Task()
t1.executable = '/bin/bash'
t1.arguments = ['-l', '-c', 'base64 /dev/urandom | head -c 1000000 > output.txt']
# Add the Task to the Stage
s1.add_tasks(t1)
# Add Stage to the Pipeline
p.add_stages(s1)
# Create another Stage object to hold character count tasks
s2 = Stage()
# Create a Task object
t2 = Task()
t2.executable = '/bin/bash'
t2.arguments = ['-l', '-c', 'grep -o . output.txt | sort | uniq -c > ccount.txt']
# Copy data from the task in the first stage to the current task's location
t2.copy_input_data = ['$Pipline_%s_Stage_%s_Task_%s/output.txt' % (p.uid,
s1.uid, t1.uid)]
# Add the Task to the Stage
s2.add_tasks(t2)
# Add Stage to the Pipeline
p.add_stages(s2)
# Create another Stage object to hold checksum tasks
s3 = Stage()
# Create a Task object
t3 = Task()
t3.executable = '/bin/bash'
t3.arguments = ['-l', '-c', 'sha1sum ccount.txt > chksum.txt']
# Copy data from the task in the first stage to the current task's location
t3.copy_input_data = ['$Pipline_%s_Stage_%s_Task_%s/ccount.txt' % (p.uid,
s2.uid, t2.uid)]
# Download the output of the current task to the current location
t3.download_output_data = ['chksum.txt > chksum_%s.txt' % cnt]
# Add the Task to the Stage
s3.add_tasks(t3)
# Add Stage to the Pipeline
p.add_stages(s3)
return p
if __name__ == '__main__':
pipelines = []
for cnt in range(10):
pipelines.append(generate_pipeline())
# Create Application Manager
appman = AppManager()
# Create a dictionary describe four mandatory keys:
# resource, walltime, and cpus
# resource is 'local.localhost' to execute locally
res_dict = {
'resource': 'local.localhost',
'walltime': 10,
'cpus': 1
}
# Assign resource request description to the Application Manager
appman.resource_desc = res_dict
# Assign the workflow as a set or list of Pipelines to the Application Manager
# Note: The list order is not guaranteed to be preserved
appman.workflow = set(pipelines)
# Run the Application Manager
appman.run()